Adaptive Context Architecture
Adaptive Context enriches the structured data the LLM operates on after each interaction. The model itself is not retrained — its input data becomes more specific over time through classification, resolution, and recomputation.
Two-pass architecture: classify intent first, then fetch only the relevant pre-computed analytics. A feedback loop recomputes context after each resolution so subsequent queries operate on fresher, richer data.
Why Traditional Architectures Fail
Static context selection wastes tokens, ignores user intent, and operates on stale data.
Data Overload
Sending all available data to the LLM wastes tokens and dilutes the signal-to-noise ratio. The model spends capacity processing irrelevant information.
Stale Analytics
Pre-computed results drift out of date without freshness guarantees. The AI narrates obsolete information, leading to incorrect or misleading responses.
Wrong Context
Static context selection ignores user intent, producing irrelevant answers. Every query gets the same generic data regardless of what the user actually needs.
Adaptive Context addresses these by classifying intent first, fetching only relevant analytics, and enforcing freshness checks before every LLM call.
The Classification Cascade
Three-layer determination with progressive fallback — from LLM intelligence to deterministic patterns to safe defaults.
Layer 1: LLM Classifier
A lightweight, low-temperature LLM call (temp 0.1, max 50 tokens) classifies the user message into a domain category. The classifier sees the last 4 conversation messages for context and returns exactly one category from a constrained enum.
If the result is a specific domain (not "general"), classification is complete — no further layers needed.
Category → Targeted Pipeline
Each classified category activates a targeted data pipeline — nothing more, nothing less. Instead of sending all data to the LLM, only relevant pre-computed analytics are fetched.
How It Works
Classify
Determine user intent via the cascade
Fetch
Pull only relevant pre-computed analytics
Assemble
Build domain-tuned prompt with valid actions
Constrain
LLM receives summaries, not raw data
Key insight: The LLM never sees raw data. It only narrates pre-computed, deterministic results. Each category maps to a specific system prompt, context loader, set of valid actions, and token budget. The LLM receives structured, auditable summaries — never raw records.
Freshness Guarantee Protocol
Pre-computed analytics can drift out of date. The freshness protocol ensures the system always works with current data, not stale snapshots.
Check Age
Query latest computedAt timestamp from DB
Stale?
Compare against staleness threshold
Trigger
Re-run analytics engine with current data
Poll
Check DB every 2s for new computedAt
Serve
Return fresh data to LLM context
Timeout Safety: If recomputation exceeds the maximum wait window, the system proceeds with the best available data and includes an analytics age note so the AI can transparently communicate data freshness. The system never blocks indefinitely.
The Adaptive Context Path
Each user interaction drives the system to become more precise through a self-compounding feedback loop. The next query always benefits from richer, fresher analytics.
User Responds
Natural language response enters the system
Raw signal captured
Classify Intent
LLM + Regex cascade determines domain
Classification improves with conversation context
Select Pipeline
Category activates targeted analytics fetch
Richer context from previous resolutions
Freshness Gate
If stale, recompute before proceeding
Latest user overrides always reflected
Resolve & Execute
LLM maps intent, code writes side-effects
Permanent classifications applied
Log & Recompute
Resolution triggers analytics recomputation
Next query gets richer, more precise context
What Accumulates Over Time
The system builds per-user context profiles across four layers. Output quality improves because input data becomes more specific, not because the model itself changes.
Structure Awareness
Entity type, ownership, partner definitions
Historical Baselines
Computed metrics, running averages
Relationship Mapping
Related-party links, payee classifications
Noise Filtering
Whitelisted entities, confirmed-clean patterns
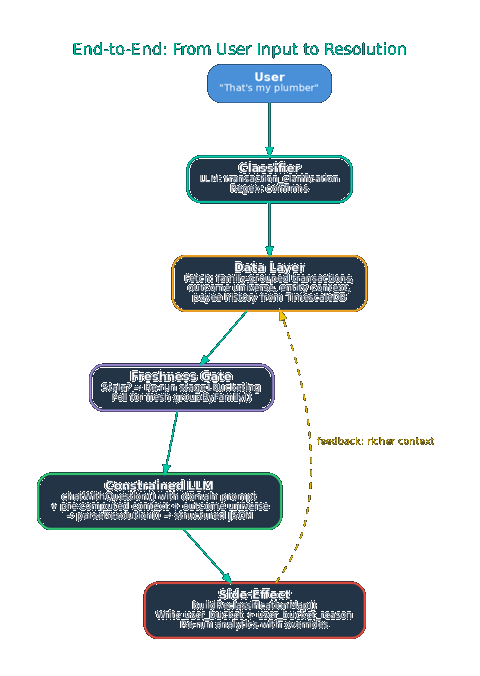
End-to-End: From Input to Resolution
Trace a concrete interaction through the full adaptive context architecture.
User Input
User provides a natural language response (e.g., identifying an entity or confirming a classification).
The Narration Principle
LLM Interprets Raw Data
- ✕ Results vary between calls (non-deterministic)
- ✕ Tokens consumed by data, not insight
- ✕ Every number is unverifiable
- ✕ Hallucination risk for reported metrics
LLM Narrates Pre-Computed Results
- Same data → same answer (reproducible)
- Tokens used for narration, not computation
- Every number traceable to a source
- Reduced hallucination risk
Enforcement at Every Stage
The pipeline enforces the narration principle at every stage: Stage 1 processing is pure deterministic rules (no LLM). Stage 2 classification and question generation use deterministic templates. Stage 3 resolution constrains the LLM to a closed outcome universe — it can only select from valid actions, never invent new ones. Side-effects are executed by deterministic code, never by the LLM.
Explore the Full Framework
Read about the purpose-built DSL, compliance workflows, and production architecture.